
对量化VC而言,最核心的问题就是:如何利用AI对初创公司进行自动化筛选?这是说量化VC需要训练筛选初创企业的模型,然后根据模型结果找到潜在投资标的。欧洲知名的量化VC(数据驱动VC投资)机构Earlybird Venture Capital合伙人Andre Retterath介绍了Earlybird的筛选方案,供大家参考~
什么使风险投资获得成功?
“情人眼里出西施”这句话同样适用于VC风险投资的成功。我们观察到,投资人从单纯的财务回报视角转向更全面的 ESG 视角,但大多数 GP 仍然将投资回报率 (ROI) 放在首位。
从投资组合层面来看,早期VC投资回报基于幂律分布,而后期和私募股权 (PE) 回报则遵循正态分布。根据最著名的幂律分布,即帕累托原则(或“80-20 规则”),早期VC投资回报受高 alpha 系数驱动,这通常导致只有 10% 或更少的投资组合带来 90% 以上的回报。
{kind=link}
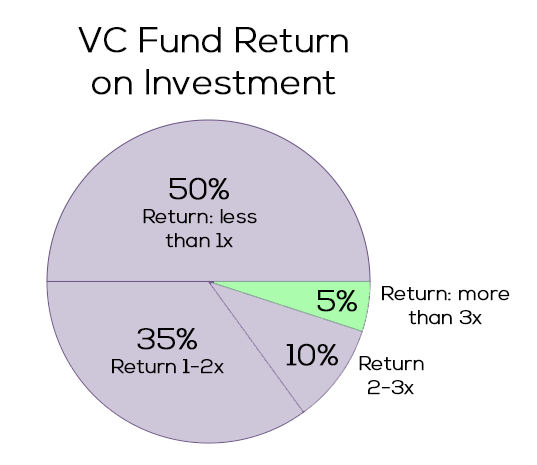
TechCrunch 提供的 VC 基金回报分布
一支表现良好的早期VC投资基金,如果投资组合中有 25-35 家初创公司,业绩则取决于一两家异常的 IPO 或并购交易,相对而言对投资减值损失则不太敏感。换句话说,早期风险投资公司注重上行(向上的回报),而成长型风险投资机构和私募股权机构(PE机构)则试图限制下行。反过来说,每一项风险投资都需要有潜力成为少数的异军突起。
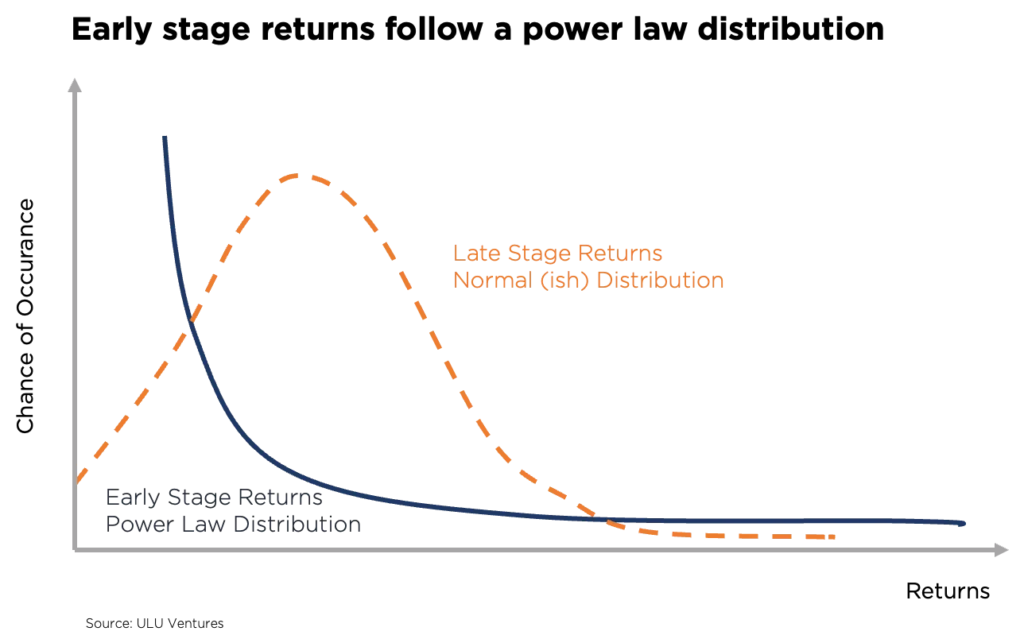
早期风险投资(幂律)与晚期风险投资(正态)的回报分布
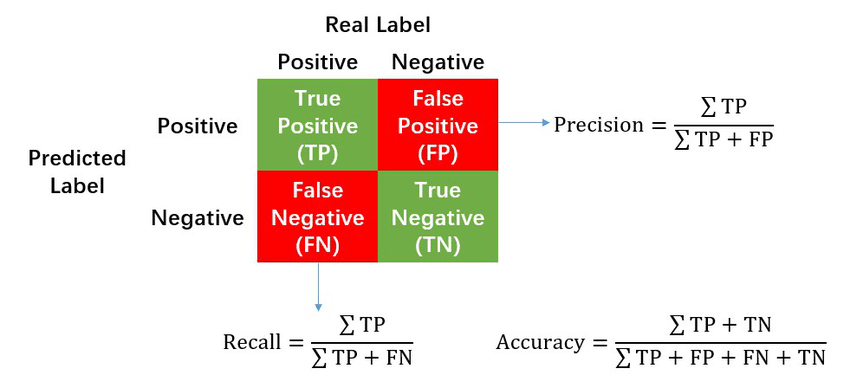
虽然早期VC投资可以承受注销其投资组合的很大一部分,但他们不能错过任何异常值。用数据语言来说:VC投资机构面临一个不对称的成本矩阵,其中假阳性(FP=决定投资但需要稍后注销)是可以接受的/成本较低,因为他们可能只会损失一次资金,但假阴性(FN=决定不投资但后来变成了一家价值数十亿美元的公司)是不可以接受的/成本较高的,因为他们错过了将资金翻几倍的机会。
这样的话,VC机构可以通过投资每家公司来降低 FN,但实际上,它们面临着自然限制,例如 1) 人力驱动的VC机构可以更详细地审查和筛选多少家公司,以及 2) 在基金规模固定、初始分配与后续分配明确划分以及考虑到公司数量的大致目标的情况下,VC机构可以投资多少家公司。因此,成功的VC机构需要以固定的投资数量作为限制来提高召回率(=减少假阴性)。
{kind=link}
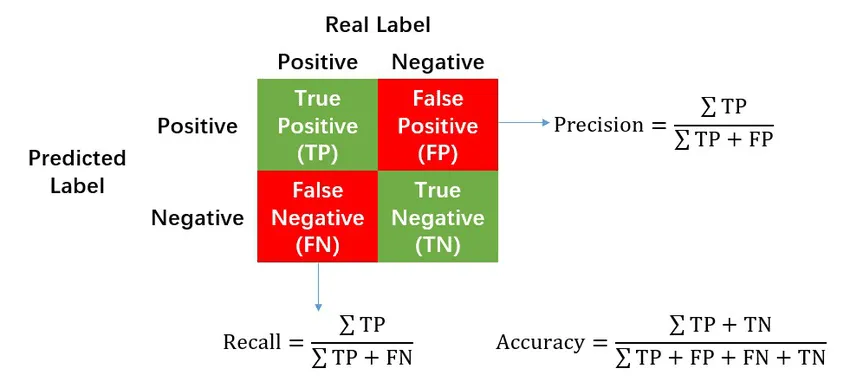
混淆矩阵是计算召回率的先决条件
消除噪音
VC机构如何在对资本约束保持敏感的同时提高召回率?在与数百家VC机构讨论他们的筛选流程后,我确定了两个重要的筛选维度和四大类筛选方法。让我们在大海捞针!
{kind=link}
- 宏观筛选
即VC机构如何平衡不同的筛选标准(例如团队、问题/市场(规模、增长、时机拉动/推动、碎片化)、解决方案/产品(USP、IP 等)、商业模式、上市动向、吸引力(产品、财务)、竞争格局、防御性、资本表、轮次结构等)。例如,团队比市场规模更重要。总的来说,将宏观层面视为一个等式,如成功分数 = a*团队分数 + b*市场分数 + … + n*x 分数;其中a到n是各个筛选标准的权重。
- 微观筛选
即VC机构如何评估个人筛选标准,例如“一名计算机科学本科生,随后读了斯坦福 MBA,在一家规模扩大的公司拥有 2 年的商业开发经验,并且有两名互补的技术创始人,这是一个很好的团队指标,而一名大学辍学生从表面消失了,然后突然以单一创始人的身份带着商业创意回来,这可能是一个不好的团队信号”。我知道这个例子很糟糕,但你明白我的意思 😉
四大类筛查方法:
- 通过投资团队进行手动选择:
现状是,大多数 VC 都处于这种状态。他们依靠自己经验范围内有限的成功案例样本来平衡选择标准(宏观)并对其进行评估(微观)。全是手动的,没有明确的剧本。每个团队成员的确定性宏观平衡(a到n )和微观评估不同,导致结果高度可变。
- 优点:高度的控制和信任
- 缺点:手动、低效、不包容、对每个团队成员都有主观性和偏见,团队内部差异巨大
- 通过记分卡进行人工选择:
一些 VC 会记下他们的宏观标准平衡(“标准 X 比标准 Y 更重要”)和微观标准评估手册(“从 O 大学毕业很棒,但从 P 大学毕业就没那么棒了”),以标准化他们的筛选流程并培训更多初级投资团队成员。试图进行确定性的宏观平衡(a到n )和微观评估,让整个团队尽可能标准化。
- 优点:高度的控制和信任,整个团队标准化
- 缺点:手动、低效、团队层面主观,可能是最不具包容性的方法,因为我们需要重叠基金中决策者的所有偏见(这又是基于非常有限的样本量),最终得到一个微小的积极微观标准交集(什么是好或坏)
- 通过记分卡自动选择:
与人工的方法非常相似,但宏观层面(a到n )的平衡以及微观层面的评估都是通过算法自动完成的。例如,我们可以确定性地定义a (团队权重)为 0.4,而b (市场权重)为 0.2,因此认为团队比市场重要两倍。在微观评估层面,我们可以定义带有关键字的简单词典来计算分数。例如,我们可以定义 0 =“退学”或“无学位”;1 =“中等大学的任何名称”或“中等大学的另一个名称”;2 =“顶级大学的名称”或“慕尼黑工业大学”;)然后计算团队得分。
- 优点:控制力强、信任度高、团队标准化、半自动化、高效
- 缺点(和人工选择类似):在团队层面上主观性较强,可能是包容性最差的方法,因为我们需要重叠基金中决策者的所有偏见(这又是基于非常有限的样本量),最终得到一个微小的积极微观标准交集(什么是好什么是坏)
- 通过机器学习进行自动选择:
最具创新性和完全自动化的方法。我们根据历史数据训练 机器学习模型(ML模型),以识别预测未来成功的模式。底层样本量很全面,并且模型会学习所有可用的模式,但它会将过去反映到未来,并且只有在回顾时才能适应不断变化的动态。
{kind=link}
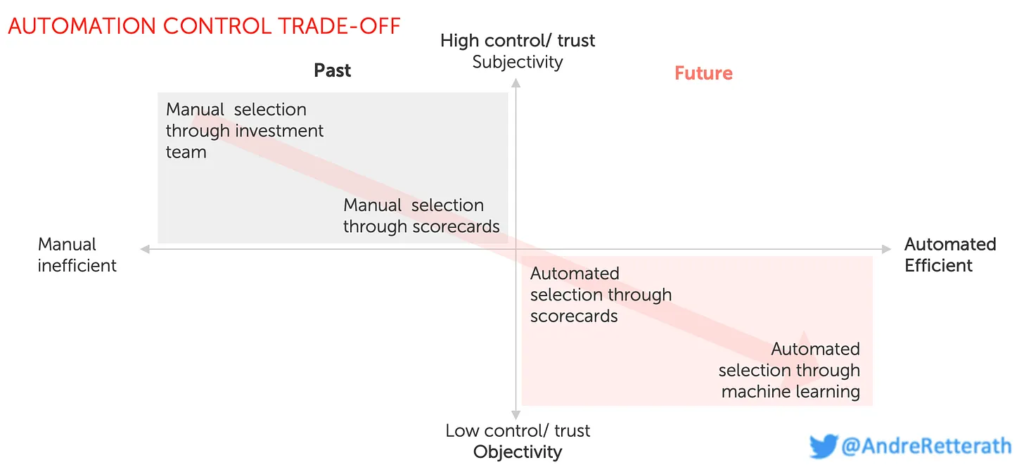
自动化控制权衡,展示四大类筛选方法
自动化 ML 方法似乎是最理想的解决方案,但目前它有两个大障碍:缺乏信任,以及它将过去反映到未来(= 仅是被动的)。
训练初创企业的筛选模型
输入
首先,我假设我们已经完成了“如何为初创公司创建单一事实来源”和“‘Sh*t in,sh*t out’ 以及为什么特征工程是 VC 的最终差异化因素”中所述的数据清理、实体匹配和特征工程。因此,让我们假设现在可以全面收集输入特征并将其作为时间序列数据集定期存储。
为了复制现实世界的设置,我们需要根据当时可用的实际数据做出继续/不继续的决定,并且最终的成功/失败在几年后才会变得明显,我们需要在t1收集输入特征并在t2收集输出数据/成功标签。
这强调了尽快收集数据的重要性,不要拖延太多。t1和t2之间的时间段越接近初始投资期(通常是 VC 基金的第 0-3 年)和退出期(通常是 VC 基金的第 7-10/11/12 年)之间的实际时间段,效果就越好。对于我们的目的,t1和t2之间的间隔大约为 5 年是最佳的。
输出
接下来,我们需要关注输出数据,即我们想要为每个观察结果预测的标签。在筛选阶段,我们感兴趣的是将好公司与坏公司区分开来,并根据成功的可能性对公司进行排名。通过这样做,我们面临着成功的确定性和由此产生的样本量之间的权衡。
这意味着什么?如果我们为每家成功上市的公司分配“1”,为所有其他公司分配“0”,我们将获得很高的确定性,但最终会得到一个相当小的样本量,只有几千家成功的公司。数据集将高度不平衡,相关成功观察的数量太少。如果我们另外根据行业和时间依赖性进行调整,样本量很快就会下降到几十或几百家成功的初创公司,统计意义将无法实现。
另一方面,我们可以将每家获得后续融资的公司分配为“1”,将所有其他公司分配为“0”。在这个例子中,我们最终会得到成功的低确定性,但样本量相当大,有几十万家初创公司。
即使我们同时根据行业、技术和时间依赖性进行调节,我们最终也会获得足够的样本量来实现统计意义。因此,我建议根据不同的确定性/样本量比率训练多个模型。
模型基准测试
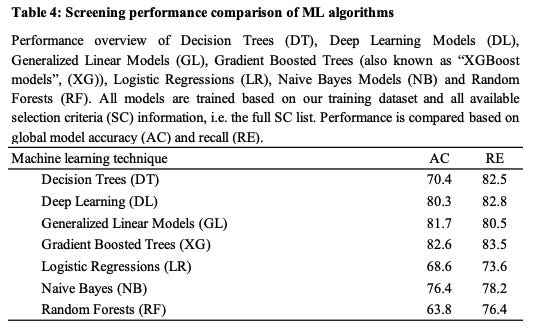
一旦我们收集了截至t1的输入数据并定义了截至t2的不同输出标签,我们就可以训练各种 ML 模型。最后,我们需要比较它们的性能,重点关注召回率。

摘自“人类与计算机:对风险投资家和机器学习算法进行投资筛选的基准测试”
{kind=link}
基于我研究中非常有限的 Crunchbase 数据集,梯度提升树/XGBoost 模型在召回率和准确率方面取得了最佳效果。重要说明的是:我认为 ML 技术/模型本身并不重要。如前所述,特征工程和数据准备更为重要。
放眼整个过程,我们的数据驱动VC投资之旅始于可扩展的数据收集和完美的实体匹配,这两项功能多年来显著提高了我们的采购覆盖率。这很棒,但也增加了渠道中的机会数量,并要求我们改进渠道中间的交易流程管理。换句话说,筛选和优先排序对于我们保持领先地位至关重要。
成功地将票证规模或地理重点等硬性标准与个人品味和统计信号结合起来比以往任何时候都更加重要。大规模实现这一点需要自动化,以及对底层系统的信任。有趣的量化VC投资游戏开始了。